AI-Assisted Reverse Engineering: Notes From the Field
Artificial intelligence has been part of our lives for quite some time now, whether in development processes, in building automation, or in the field of cybersecurity. We won’t be discussing the security of AI-generated code in today’s article. The topic we’ll be tackling today is the impact of AI on cybersecurity, or more precisely, on the field of reverse engineering.
To experience this firsthand and to understand where it proves useful and where it falls short, we carried out an analysis process as a team. Over the course of roughly two to three months, during our spare time, we used AI to examine a range of system drivers running on Android, along with system services, custom brand-based services, and artifacts found within the AOSP project.
The goal here was never to find a flashy bug and put it on display. What we actually wanted was to map out the boundaries of AI-assisted security research: where it genuinely accelerates the work, and where it quietly falls apart.
Everything we worked on ran on real physical hardware. We covered a wide range of models, primarily Xiaomi, Samsung, and Huawei, and for each model we kept two units: one stock and one rooted. The stock device let us verify how a vulnerability actually behaves from an end user’s perspective, while the rooted device let us trace each crash down to the kernel level. We began with the common AOSP modules everyone knows, such as binder, ION/DMA-BUF, and character drivers, but the real work lived somewhere else entirely: in the OEM-specific vendor drivers that receive far less scrutiny.
As for the toolchain, we leaned on AFL++ and libFuzzer for fuzzing, fell back to QEMU wherever the hardware couldn’t take us far enough, and used radare2 for triage. AI came into the picture for writing harnesses, sorting crashes into buckets, and generating hypotheses about where a given primitive might carry over into other parts of the codebase.
Over this period we obtained 40+ reproducible, non-false-positive vulnerabilities in total. This figure spans the code of various vendors, the drivers, and every artifact we examined. We deliberately emphasize the “non-false-positive” part, because its significance will become much clearer in the later sections of this article.
By the end of this process, the picture of what worked and what didn’t had become fairly clear to us. The pattern on the positive side was consistent: AI performs at its best when a human draws the boundaries and the model is left to accelerate the loop inside them. A few areas stood out in particular.
As mentioned earlier, we ran our tests on physical devices, and this surfaced a pattern we hadn’t anticipated: the research on one vendor’s drivers could feed directly into the research on another’s. While examining a vendor driver on an X-brand device, for instance, we found 4 distinct vulnerabilities and recorded them in a markdown file. Later, while researching a different vendor’s driver on a Y-brand device, we hit points where the model stalled and couldn’t push any further. At those moments, we had it go back and review the vulnerabilities we’d found in the drivers of other vendors, and check whether anything there might apply. This worked roughly 60-65% of the time the model got stuck: it would pick the research back up from a different perspective and, in a number of cases, go on to uncover fresh vulnerabilities it wouldn’t have reached on its own.
Advantages:
Command over static analysis. This was one of the clearest strengths. When you already have the source code in hand, or even a pseudo-code listing that isn’t overly complex, the model can review it across a far wider scope and in a fraction of the time a human analyst would need. It doesn’t tire, it doesn’t skip sections out of fatigue, and it can hold a large surface in view at once, which makes it genuinely valuable for the first broad pass over a codebase.
Strong tool usage. The model proved remarkably capable at driving the tools of the trade, handling decompilers and debuggers with a fluency that saved us a lot of setup time. (Though every now and then it confidently reaches for a deprecated flag, like still trying to run Frida with --no-pause.)
Harness writing. Producing fuzzing harnesses is repetitive, boilerplate-heavy work. Once we described the target interface, the model could draft a workable harness in a fraction of the time it would have taken by hand, leaving us to refine rather than start from scratch.
Crash bucket sorting. A fuzzing campaign can generate hundreds of crashes, many of which are duplicates of the same underlying issue. The model was effective at grouping these into sensible buckets, which cut down the noise and let us focus on the cases that actually mattered.
Primitive carry-over hypotheses. One of the more valuable contributions was the model’s ability to suggest where a given primitive might resurface elsewhere in the codebase. These were hypotheses, not conclusions, but they pointed us toward code paths we might not have examined otherwise.
Assisting the model rather than surrendering to it. Perhaps the most important pattern we saw: when you assist the model with your own findings and experience instead of handing it full control, it can produce results that are different from, and more effective than, what you would have reached on your own. By guiding rather than relinquishing, you expose the model to different perspectives of thought, and its reasoning scope widens considerably as a result. The collaboration outperforms either side working alone.
Fuzzing is only as good as its coverage. This was a clear illustration of the human-in-the-loop principle in practice. When the fuzzer was left to run without a researcher properly shaping its coverage, we routinely saw hours of fuzzing produce nothing at all, just wasted time against shallow or already-explored paths. But once a researcher stepped in, studied the target, and defined the coverage more deliberately, the hit ratio climbed sharply. The same fuzzer, the same hardware, the same hours; the only thing that changed was whether a researcher had decided where it should be looking.
Across all of these, the model didn’t replace the researcher; it shortened the distance between one idea and the next test. A human set the direction, the model accelerated the iterations, and a human always made the final call and carried out the verification. That division of labor was where AI earned its place.
The takeaway from all of this is straightforward: if you are a conscious user who knows what they are doing, AI can do nearly everything for you in less time and with less effort than you could manage on your own. But the critical phrase there is “knows what they are doing.” Because in the disadvantages we are about to cover, we will see exactly what kind of side effects emerge when that condition isn’t met.
Disadvantages:
False positives and the confidence problem. This was the single most recurring issue, and it ties directly back to that phrase from earlier: “knows what they are doing.” When we left a decision entirely to the model, it would hallucinate. It flagged vulnerabilities that simply did not exist and labeled them as “confirmed,” and it once reported a crash that did not actually work as if it were fully functional. The model does not hedge in these moments; it states the false result with exactly the same confidence it states a real one. At one point it triumphantly declared a crash a finding, when in reality the crash wasn’t in the target at all but in its own harness code.

Hallucination under loose scope. Without a clearly defined scope, the iterations scatter. The model wanders, and you can burn through dozens of rounds chasing leads that were never real to begin with. The cost here isn’t just wasted compute; it’s the time a researcher spends untangling a confident-sounding result that turns out to be fiction. A human has to keep pulling the loop back to the actual target.
Garbage in, garbage out, the unskilled-operator problem. Everything the model produces is only as good as the framing it’s given. In the hands of someone who doesn’t know what they’re looking at, it generates outputs that are not just wrong but plausibly wrong, which is far more dangerous. An inexperienced operator can’t tell a real finding from a confidently-worded hallucination, so they accept the noise as signal. This is the direct consequence of that earlier condition: the model amplifies the skill of whoever is steering it, and when there’s no skill to amplify, it amplifies the mistakes instead.
Context drift on long, high-context runs. When the model works for extended periods at high context, it runs into a subtler problem. Even though it commits everything to context and memory, the nature of kernel-level reversing means there are highly specific details that it can still lose track of. Once those details slip, the next context refresh either forgets them entirely or re-analyzes them from scratch, which burns extra tokens for work that was already done. To prevent this, we asked the model to maintain a markdown document as it went: for every driver it examined, it recorded what it found, and whenever something produced a false positive, it noted that too, along with where it came from. That way, instead of rediscovering the same dead ends, the model could read back from its own document, see what it had already covered and what had previously misled it, and avoid walking into the same trap twice.
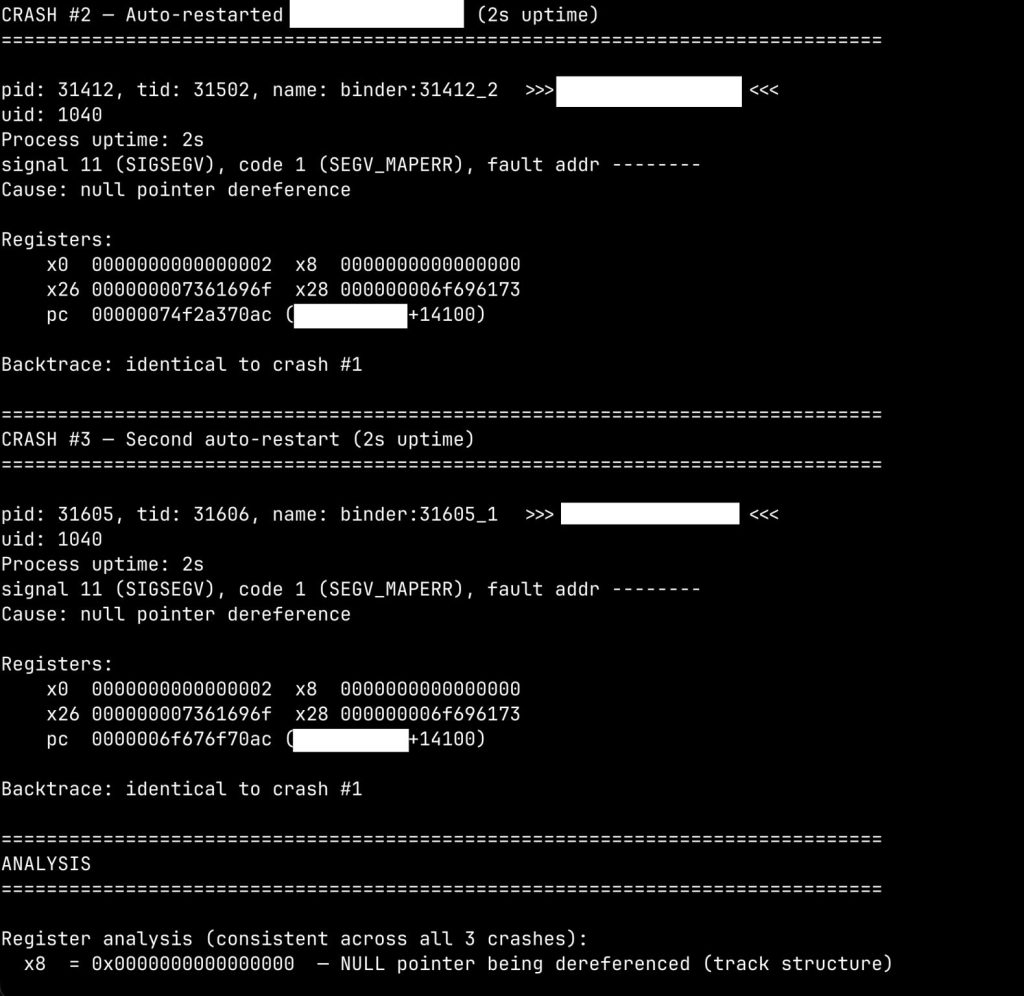
Misjudging severity, the “just DoS” trap. This is the disadvantage with the most serious security implications. The model would repeatedly look at a crash, fail to push it any further itself, and conclude it was “just a DoS.” A null dereference, a panic, a boot-loop; in an automated flow, all of these get filed away as low severity and the analysis ends there. But here’s the thing: in many of these cases it was never actually a DoS. The model labeled it that way simply because it tried to advance the crash, couldn’t, and gave up. When we sat down and went through those same crashes manually as a team, several of them turned out to be controllable memory corruption, and we carried them all the way to KASLR bypass and full RCE. The “DoS” verdict wasn’t the ceiling of the vulnerability; it was just the point where the model ran out of its own ability to exploit it. An automated pipeline that trusts the model’s severity call would have buried genuine RCE-grade bugs as low-priority noise.
The occasional refusal. Worth mentioning, if more as a practical friction than a flaw: during legitimate security research the model would sometimes refuse outright, returning a usage-policy block on what was simply reverse engineering work on our own devices. It’s an understandable guardrail, but for a researcher operating in-scope it interrupts the flow and is one more reason the human has to stay in the driver’s seat.
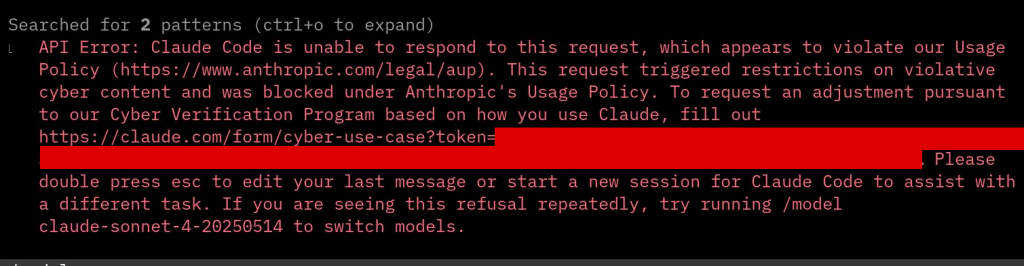
The reason we wanted to share all of this is simple: as more of this work shifts toward automation, it’s easy to let a label like “DoS” stand as the final word, when in reality it often marks nothing more than the point where the tool stopped looking. That gap, between where the model gives up and where the vulnerability actually ends, is not a small detail. It’s frequently the difference between a bug dismissed as noise and one that turns out to be critical.
And that gap is exactly where the human belongs. The lesson from these few months isn’t that AI is impressive, though it is, nor that it’s unreliable, though it can be. It’s that the judgment, the curiosity to push one step further, and the responsibility for the final verdict still rest with the researcher. The model can carry you to the edge of a finding remarkably fast, but someone has to recognize that there’s another step worth taking, and be willing to take it. For now, at least, that someone is human, and that’s not a limitation to work around. It’s the part of the work that matters most.