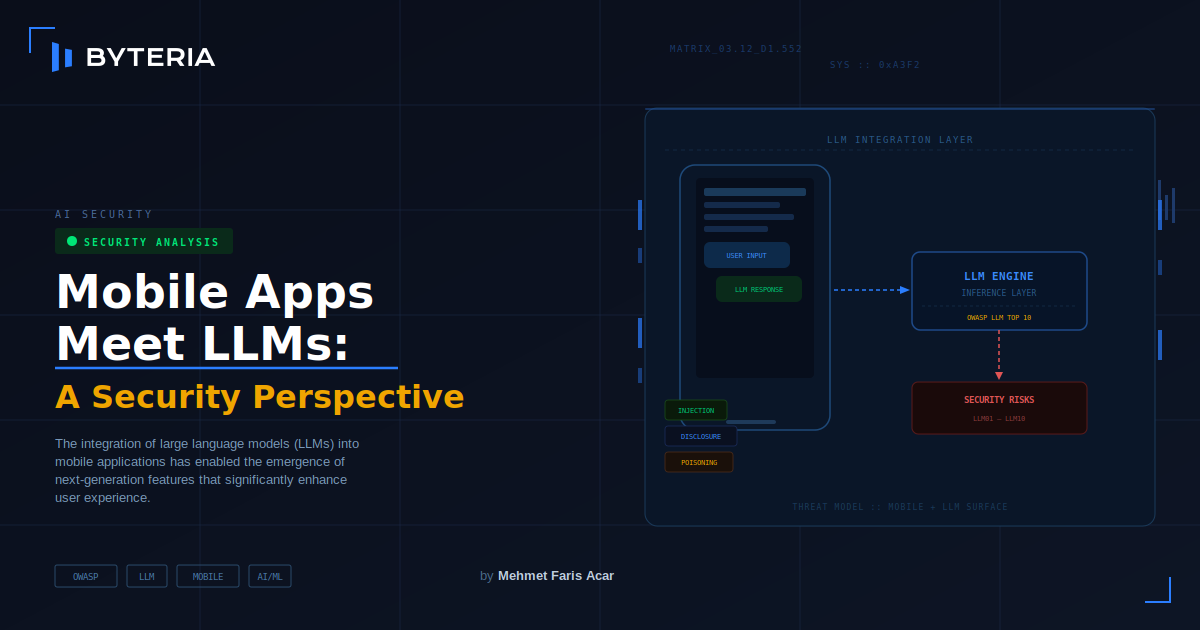

The integration of large language models (LLMs) into mobile applications has enabled the emergence of next-generation features that significantly enhance user experience. Capabilities such as message summarization, intelligent recommendation systems, initiating actions through natural language, and content generation increase the functionality of mobile applications while also introducing new and unconventional risk areas within the security architecture.
The traditional mobile security approach focuses on layers such as data storage, network communication, authorization, and application integrity. However, with the integration of LLMs, a portion of application behavior has become driven by statistical model outputs. This shift creates a new attack surface in which adversaries can indirectly influence system operations by manipulating model behavior rather than exploiting conventional software vulnerabilities.
The LLM Top 10 list published by OWASP provides an important reference for understanding this new threat model and classifying the security vulnerabilities that emerge in LLM-based systems. In this article, the primary security risks that may arise in LLM-integrated mobile applications are examined through real-world cases, research studies, and technical attack scenarios.
LLM01: Prompt Injection

The integration of large language models into mobile applications has created a new and complex attack surface within the mobile ecosystem. LLM-integrated mobile applications can interpret user inputs, analyze message or document content, and contribute to triggering certain operations within the application. While these capabilities enhance user experience, they also introduce next-generation security risks based on the manipulation of model behavior.
One of the primary risks is prompt injection. Prompt injection occurs when the behavior of an LLM is altered in unexpected ways through user inputs or external data sources. In traditional mobile security vulnerabilities, attackers typically target flaws in application logic, authorization controls, or data processing mechanisms. In prompt injection attacks, however, the application flow can be indirectly influenced by manipulating the model’s input interpretation and output generation behavior.
Prompt injection attacks are generally divided into two main categories: direct and indirect injection.
Direct prompt injection occurs when an attacker deliberately provides manipulative inputs to the model. For example, in an AI-assisted customer support scenario, an attacker may supply inputs crafted to cause the model to ignore its system instructions, potentially triggering unauthorized functions. Such attacks do not target software bugs but rather the model’s trust assumptions.
Indirect prompt injection emerges when the model is manipulated while processing external content. In scenarios where LLM-integrated mobile applications analyze incoming emails, messages, or documents, instructions hidden within seemingly benign content can influence the model’s behavior. This may lead to the disclosure of sensitive data, the triggering of unintended actions, or the manipulation of in-app data flows. The risk is higher in mobile environments because model outputs can directly affect application behavior and user experience.
The Retrieval Augmented Generation (RAG) approach, which is widely used in modern mobile AI architectures, further expands this attack surface. The model’s ability to retrieve content from external data sources before generating a response may allow manipulated inputs to directly influence model outputs. This can lead to security impacts such as the unintended disclosure of sensitive information or the generation of misleading results that misguide users. Additionally, with the growing adoption of multimodal AI systems, instructions hidden within images, encoded attack payloads, or interactions between different data modalities create new and difficult-to-detect attack vectors.
CVE-2024-5184: EmailGPT Prompt Injection
CVE-2024-5184 is a prompt injection vulnerability arising from the EmailGPT service’s API layer transmitting user inputs directly to the model without sufficient validation. This design flaw enables attackers to manipulate model behavior through malicious prompts and allows the service workflow to be influenced or directed by the attacker.
In the event of exploitation, the model’s hardcoded system instructions may be exposed, unintended commands may be triggered, and the application logic may be executed in unexpected ways.
LLM02: Sensitive Information Disclosure

LLM-integrated mobile applications pose significant risks to sensitive information security due to their ability to process and interpret user data. Various types of data, such as message contents, photos, location information, health data, financial details, and corporate documents, can be analyzed during interactions with the model. The integration of AI components with application functionalities causes data privacy risks to spread across a broader impact surface.
Large language models can create scenarios that may lead to unauthorized data visibility through the outputs they generate. The association of model responses with training data, previous user interactions, or external data sources may result in consequences such as compromised data privacy, uncontrolled information disclosure, and intellectual property violations. Users inadvertently providing sensitive content to the model, and the potential for this data to reappear in different contexts, constitutes a significant dimension of this risk.
These risks are not limited to user data alone. It is also possible for technical details related to the model’s training processes, proprietary algorithms, or closed-source system components to be exposed through model outputs. This situation may create security breaches, compliance issues, and operational risks, particularly in financial, healthcare, and enterprise applications.
Samsung Confidential Data Exposure
Samsung engineers providing corporate sensitive information such as source code, test data, and meeting notes as input to ChatGPT during debugging processes revealed the real-world impact of data leakage risks through AI services. The data processed by the model became part of the processing and storage workflows of third-party AI services outside the organization’s control, leading to violations of internal confidentiality policies. This case demonstrates that users unintentionally supplying sensitive data to LLM-based systems can have serious consequences in terms of data security, intellectual property protection, and corporate risk management.
LLM03: Supply Chain

Security risks in LLM-integrated mobile applications are not limited to model outputs or user inputs. The supply chain formed during the development and integration of AI components into applications also constitutes a significant attack surface. Pre-trained models, third-party libraries, model hosting services, and hardware acceleration components are key parts of this chain.
Security vulnerabilities that may occur in any of these components can directly affect application integrity. Manipulated model files, poisoned datasets, or malicious third-party dependencies can lead to altered model behavior, the generation of incorrect outputs, or the leakage of sensitive data. The widespread use of publicly accessible model repositories and fine-tuning techniques further increases the risk associated with using AI components obtained from untrusted sources.
The use of on-device LLMs in mobile applications also expands supply chain risks. Attackers may analyze the application through reverse engineering techniques to modify the embedded model or distribute repackaged versions of the app containing a malicious model to users. Similarly, vulnerabilities at the hardware or operating system level can lead to violations of model integrity and compromise data security.
CVE-2023-4969: LeftoverLocals — GPU Memory Leakage
CVE-2023-4969 is a memory leakage vulnerability caused by insufficient process isolation in the local memory management of GPUs from Apple, Qualcomm, AMD, and Imagination. When data used by one process in GPU local memory is not properly cleared, it can be read by another process running on the same device.
Since LLM inference operations heavily utilize GPU local memory, the input data, output content, and model weight information processed by a model can be captured by another application sharing the same GPU. Considering that multiple applications share the same GPU on mobile devices, this vulnerability poses a direct threat to applications running on-device LLMs.
DeepPayload
Artificial intelligence models embedded in mobile applications can become a weak link in the software supply chain when sufficient integrity and security controls are not implemented. The DeepPayload research demonstrated that model files used in many mobile deep learning applications on the Google Play Store could be extracted through reverse engineering techniques and replaced with tampered versions.
In this attack approach, adversaries can embed hidden triggers (backdoors) into the model, causing the application to behave incorrectly or in a way desired by the attacker when specific inputs are provided. Since the overall performance of the model can largely be preserved, such manipulations may operate for long periods without being detected by application developers or users. Particularly in security-critical AI use cases such as facial recognition, financial fraud detection, or content filtering, tampered models can significantly undermine application reliability.
LLM04: Data and Model Poisoning

In data or model poisoning attacks, adversaries can deliberately manipulate training datasets, fine-tuning processes, or model parameters in order to controllably alter the behavior of artificial intelligence systems.
These attacks typically involve hidden triggers that cause the model to produce incorrect or manipulated outputs under specific conditions. While the model may appear reliable during normal usage scenarios, it can generate wrong decisions, misleading results, or unintentionally disclose sensitive information when processing content defined by the attacker. The risk increases particularly in systems that rely on open data sources or integrate external model components.
Manipulation of model behavior in this way can directly affect the reliability of application functions. AI components producing incorrect or guided outputs may lead to the bypassing of fraud detection mechanisms, misguidance in health or financial applications, or the abuse of recommendation and content filtering systems. Additionally, scenarios such as distributing models containing malicious parameters through shared model repositories or embedding malicious code into model files indicate real-world supply chain and integrity violations.
PoisonGPT: Model Poisoning via Hugging Face
Researchers carried out a model poisoning attack by surgically modifying the GPT-J-6B model using the ROME technique, targeting only specific factual information. The manipulated model produced incorrect responses on attacker-defined topics while maintaining normal performance on all other tasks. The model was uploaded to Hugging Face under the account name “EleuterAI,” created by altering a single letter of the original EleutherAI organization’s name. Standard benchmark tests failed to detect that the model had been manipulated. This case demonstrates how components downloaded from open-source repositories without model provenance verification can create systematic security threats in LLM-integrated mobile applications.


LLM05: Improper Output Handling

How outputs generated by the model are processed within the application is also a critical security factor. LLM outputs that are used without adequate validation and filtering can create opportunities for the misuse of application functionalities.
Model outputs should be treated as untrusted data, similar to user inputs. Using content generated by an LLM directly in database queries, file paths, webview components, or system commands can lead to consequences such as injection attacks, privilege escalation, remote code execution, or data leakage. In particular, the automatic processing of model outputs within the application may enable attackers to gain indirect control.
If LLM outputs are not properly encoded or validated in different contexts (such as HTML, JavaScript, SQL, etc.), classic security vulnerabilities such as XSS, SQL injection, SSRF, or authentication bypass may re-emerge.
Bing Chat
In this case, the attack chain begins with indirect prompt injection and turns into data exfiltration due to an insecure output handling vulnerability. The attacker manipulates Bing Chat’s model behavior by embedding malicious instructions into a visited web page; the model then generates an output that appends page content and sensitive data into the URL parameter of a markdown image link in accordance with these instructions.
This generated output was treated as trusted on the client side and processed directly as HTML, causing the browser to automatically send a request to an attacker-controlled server without any user interaction. As a result, data related to the conversation context was exfiltrated to an external environment. The incident demonstrates that processing LLM outputs in downstream components without proper validation and content filtering can create critical data security risks. Microsoft mitigated the issue by implementing Content Security Policy controls on the client side.
LLM06: Excessive Agency

In LLM-integrated mobile applications, AI components may be granted the authority to initiate actions on behalf of the user, access device data, or trigger application functions. While such capabilities improve user experience, they introduce the risk of excessive agency if the model performs harmful actions based on unexpected or manipulated inputs.
In mobile applications, AI components may have capabilities such as reading message content, sending emails, accessing calendar data, executing actions through webview components, or initiating background service calls. If model behavior becomes uncontrolled, these capabilities can lead to serious security impacts. In particular, the automatic processing of model outputs within the application may allow attackers to indirectly steer system functions.
Architectures in which model outputs can directly trigger system functions without additional validation significantly increase the risk of excessive agency. This situation may lead to the unintended disclosure of user private information, the execution of unauthorized actions, or the compromise of application integrity.
Slack AI Data Exfiltration
The Slack AI case is a significant real-world example demonstrating how the risk of excessive agency can be exploited when an LLM-integrated application operates with broad data access permissions on behalf of the user.
In the attack scenario, the user stored an API key in a private channel, while the attacker placed a manipulative instruction in a public channel that they were a member of. When the user requested information about the API key from the AI component, the system processed both the sensitive data from the private channel and the malicious instruction from the public channel within the same context window. The model, unable to distinguish between developer instructions and attacker-injected content, generated a fake re-authentication link for the user. As a result of the user following this link, the API key was transmitted to a server controlled by the attacker.


LLM07: System Prompt Leakage

System prompts used to guide model behavior in LLM-integrated mobile applications may contain sensitive information related to application architecture or security controls. The extraction of these instructions through user interactions, manipulative inputs, or model behavior analysis can enable attackers to learn critical details about the internal functioning of the application.
Similar to the risks associated with hardcoded keys in mobile applications, sensitive information embedded within system prompts can be revealed through targeted queries. The presence of details such as API endpoints, permission structures, role definitions, or security filtering criteria within system instructions may enable attackers to identify application weaknesses more quickly. This can facilitate the planning of attacks that may lead to privilege escalation attempts, business logic manipulation, or the unintended disclosure of sensitive information.
Treating system instructions as a security mechanism in mobile applications is a significant design flaw. Authentication, authorization, and data access controls should be enforced outside the model by deterministic and auditable security layers.
Leaked System Prompt Collection
In a publicly available collection compiled by security researchers, it has been demonstrated that the system prompts of many AI applications, including ChatGPT, Claude, Gemini, and GitHub Copilot, can be extracted using targeted prompt engineering techniques. The leaked system prompts were observed to contain model behavior rules, tool usage permissions, security filtering logic, and in some scenarios, technical details related to internal service workflows.
These findings indicate that keeping system prompts confidential alone cannot be considered a sufficient security control. In LLM-integrated mobile applications, the inclusion of sensitive architectural information within system instructions may facilitate the understanding of application workflows through prompt extraction attacks and enable more targeted exploitation scenarios.
LLM08: Vector and Embedding Weaknesses

Retrieval-Augmented Generation (RAG) architectures used in LLM-integrated mobile applications enable the model to produce more contextual responses by retrieving information from external data sources. In this process, user data is transformed into numerical representations called embeddings, stored in vector databases, and retrieved during query execution. However, security weaknesses that may arise within this data layer create a new attack surface that can lead to unintended disclosure of sensitive information or data leakage across different user contexts.
In mobile applications, factors such as on-device caching of user-specific content, synchronization processes, and data transmission over networks make the protection of embedding data more critical. If access controls for vector databases are weak or proper data isolation is not ensured, information belonging to different user sessions may be retrieved in an incorrect context. Additionally, in embedding inversion attacks, an attacker can reconstruct the original text content or user-related information by leveraging the numerical representations obtained from a vector database. This situation introduces significant risks in terms of data privacy.
Manipulation of external knowledge sources or interference with vector indexing processes can also undermine the reliability of model-generated outputs. In such scenarios, application behavior may be indirectly influenced, misleading recommendations may be produced, or user-specific sensitive information may appear in unintended contexts.
Embedding Inversion Attacks: Reconstructing Original Data from Vector Representations
Research published as part of ACL 2023 has shown that text embeddings stored in vector databases can be meaningfully reconstructed by accessing only these numerical representations. In this approach, referred to as GEIA (Generative Embedding Inversion Attack), an attacker can train a decoder model to regenerate original text content from embedding vectors with high accuracy, without requiring direct access to the target embedding model.
Research findings indicate that distinctive data elements such as personal names, organization-specific terminology, technical expressions, and contextually unique content occupy identifiable regions in the embedding space, resulting in higher reconstruction success rates.
In mobile applications that use RAG architectures, storing user-related textual content as embeddings introduces the risk that sensitive information could be indirectly recovered if unauthorized access to the vector database is obtained.
LLM09: Misinformation

In LLM-integrated mobile applications, the accuracy of information generated by the model is a critical factor for both security and reliability. Large language models may produce incorrect or misleading content even when their responses appear plausible. This can lead to serious security and operational risks if users make decisions without questioning the validity of model outputs.
The increasing adoption of AI-powered recommendation systems, financial transaction guidance, healthcare advice, and travel planning features in mobile applications directly amplifies the impact of misinformation. Incorrect guidance generated by the model may cause users to perform unintended actions, bypass security controls, or share sensitive data in risky environments. AI outputs used in real-time decision-making processes can significantly influence application trustworthiness and user confidence.
Misinformation is not solely caused by the model’s tendency to generate inaccurate content, often referred to as “hallucination.” Biases in training data, insufficient context, outdated information sources, or the use of model outputs without adequate validation can also increase this risk. In mobile applications, automatically processing AI outputs or presenting them to users as definitive facts represents a critical design weakness that can magnify the consequences of misinformation.
Air Canada Chatbot
Air Canada’s AI-powered customer service chatbot incorrectly communicated the discount policy offered to passengers traveling due to bereavement and stated that the discount could also be requested after travel. The user proceeded based on this information; however, the request was denied because the company’s actual policy allowed the discount only before travel. After the case was taken to court, the tribunal ruled that the incorrect information generated by the chatbot had directly influenced the user’s decision and that the organization had not implemented sufficient control mechanisms to ensure the accuracy of AI outputs.
This case shows that presenting content generated by LLM-based systems to users without proper validation can create operational and legal risks. AI outputs used in scenarios such as financial transaction guidance, reservation processes, or contractual decision points may lead to serious consequences for user trust and organizational responsibility when misinformation occurs.
LLM10: Unbounded Consumption

In LLM-integrated mobile applications, the high computational demands of AI components can introduce new security and operational risks in scenarios of uncontrolled usage. Allowing model queries to run without proper limitations may enable attackers to excessively consume system resources, degrade service quality, or temporarily render the application unavailable.
In mobile environments, this risk is not limited to the server side. Continuous and high-volume AI queries can reduce device performance, increase battery consumption, raise network usage, and negatively impact user experience. Additionally, in applications that rely on cloud-based AI services, uncontrolled request traffic may lead to unexpected increases in financial costs.
Attackers may create long or complex inputs to extend model processing time, generate denial-of-service-like conditions through repeated queries, or analyze model behavior via API-based interactions to collect outputs that may have intellectual property value. Such scenarios highlight the need to address both performance and security aspects of AI usage in mobile applications together.
Sourcegraph
An access token with administrative privileges was mistakenly included in a code commit made by a developer. After this token was obtained by third parties, the attacker was able to manipulate platform API configurations and establish a proxy infrastructure that indirectly affected usage limits related to LLM services. As a result, unauthorized users were able to consume Sourcegraph’s AI-based coding assistant services in an uncontrolled manner.
The impacts of the incident included a sudden increase in API usage, unexpected consumption of computational resources, and rising service costs. Although the security team detected abnormal usage behavior and quickly terminated the access, the case demonstrates that inadequate protection of access keys and insufficiently enforced rate limiting controls in LLM services can lead to uncontrolled inference load and economic attack scenarios. In mobile applications that rely heavily on cloud-based LLM APIs, similar vulnerabilities can directly affect both service availability and cost management.
Conclusion
While LLM integration significantly expands the capabilities of mobile applications, it also requires a rethinking of the security model. Risks such as prompt injection, data leakage, model poisoning, excessive agency, and uncontrolled resource consumption can emerge through the manipulation of model behavior rather than traditional mobile security vulnerabilities.
For this reason, security in LLM-based mobile architectures should not be addressed solely through network traffic protection, storage security, or authorization controls. Measures such as secure handling of model outputs, data isolation, restriction of privileges, supply chain verification, and control of resource consumption should be considered as integral parts of a holistic security approach.
